(Leetcode) 3 - Longest Substring Without Repeating Characters
New Year Gift - Curated List of Top 75 LeetCode Questions to Save Your Time
위 링크에 있는 추천 문제들을 시간이 있을때마다 풀어보려고 한다.
https://leetcode.com/problems/longest-substring-without-repeating-characters/
문자열과 관련된 문제이다.
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
if len(s) == 0:
return 0
characters = list(s)
longest = -1
def findLongestSubstring(start):
exist = {}
length = 0
for i in range(start, len(characters)):
if characters[i] in exist:
return length
else:
exist[characters[i]] = True
length += 1
return length
for i, char in enumerate(characters):
longest = max(longest, findLongestSubstring(i))
return longest
한번에 통과는 하였지만 매우 결과가 안좋게 나왔다.
그래서 다른 사람의 코드를 확인해보았다.
다른 사람들이 푼 방식
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
if len(s) == 0:
return 0
temp = []
longest = 0
for char in s:
if char in temp:
temp = temp[temp.index(char) + 1:]
temp.append(char)
longest = max(longest, len(temp))
return longest
똑똑하게 접근한 것 같다.
temp를 통해 최대로 긴 문자열을 저장해두고, 동일한 글자가 나오면 앞에서 해당 글자를 제거하고 뒤에 해당 글자를 추가하는 방식을 택하였다.
Java로 다시 풀어보기 (queue를 사용해서 풀기) (240603)
위 글을 보지 않고 자바로 다시 풀어봤다.
public int lengthOfLongestSubstring(String s) {
if (s.isEmpty()) {
return 0;
}
Queue<Character> queue = new LinkedList<>();
int start = 0;
int end = 0;
int longest = 0;
while (pointer < s.length()) {
char _char = s.charAt(pointer);
while (queue.contains(_char)) {
queue.remove();
}
queue.add(_char);
longest = Math.max(longest, queue.size());
pointer++;
}
return longest;
}
TC, SC
시간 복잡도는 O(n^2) 이고, 공간 복잡도는 O(n) 이다.
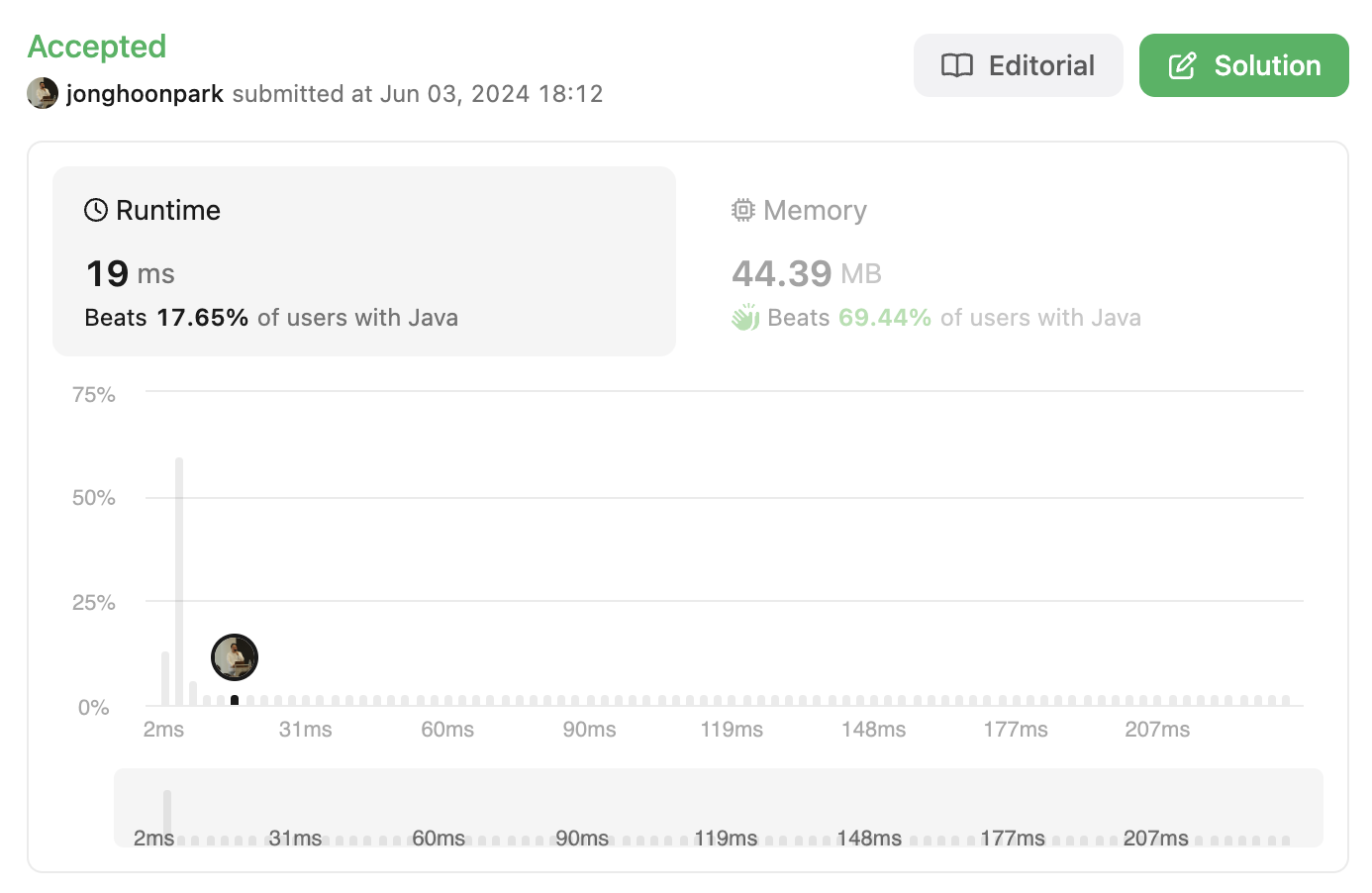
아무래도 시간을 더 줄여줘야 할 것 같다.
좀 더 최적화 해보기
contains 에서 시간을 많이 뺏는것 같다는 생각이 들었다. (순회 탐색 하려면 O(n) 이니깐)
중복이 되면 안된다는 점에서 Set을 사용했다.
class Solution {
public int lengthOfLongestSubstring(String s) {
if (s.isEmpty()) {
return 0;
}
Set<Character> set = new HashSet<>();
int pointer = 0;
int longest = 0;
while (pointer < s.length()) {
char _char = s.charAt(pointer);
while (set.contains(_char)) {
set.remove(s.charAt(pointer - set.size()));
}
set.add(_char);
longest = Math.max(longest, set.size());
pointer++;
}
return longest;
}
}
TC, SC
시간 복잡도는 O(n) 이고, 공간 복잡도는 O(n) 이다. 내부 while이 그대로 있지만 O(n)으로 적은 이유는 hash set의 경우 search 하는데 드는 비용이 O(1) 이기 때문이다.
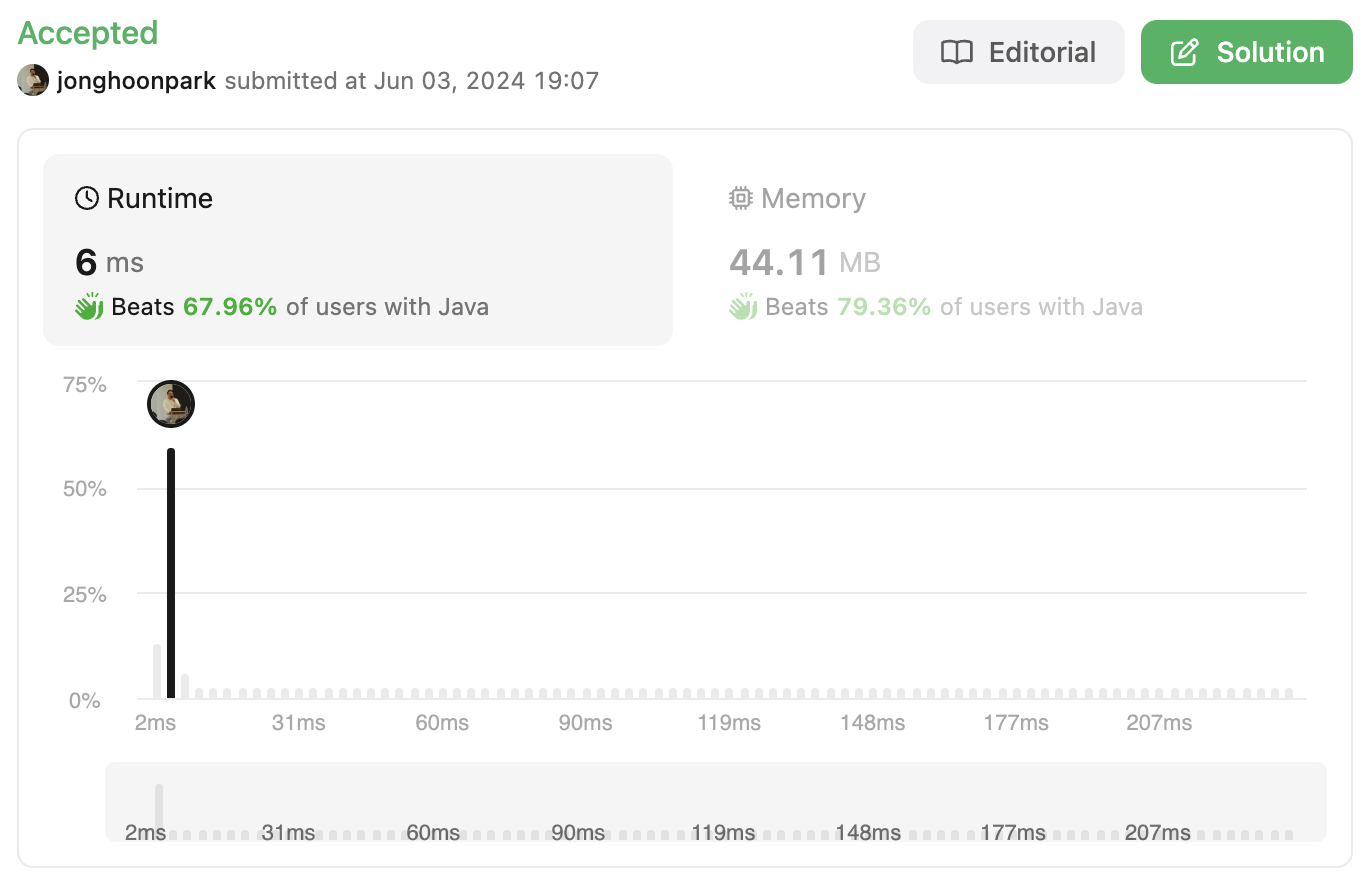
결과적으로 시간이 많이 줄어들었다.